Tutorial: Model Parallelism through Horizontal and Vertical Layer Sharding
This tutorial demonstrates how to use the Wrapyfi to shard a neural network across multiple machines.
Methodology
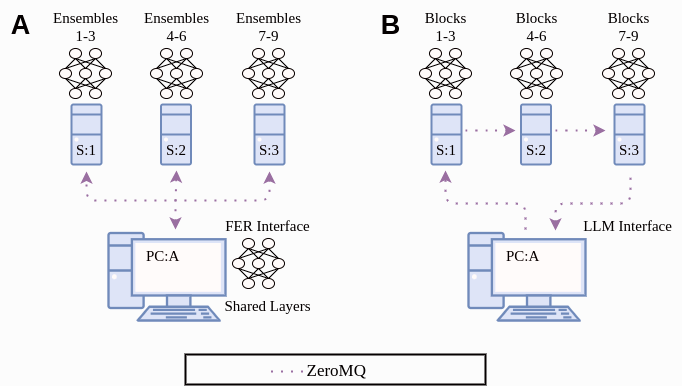
Fig 1: Sharding neural model layers A) horizontally and B) vertically.
We execute the inference script on four machines. The shared layer weights are loaded on an NVIDIA GeForce GTX 970 (denoted by PC:A in Figure 1) with 4 GB VRAM. Machines S:1, S:2, and S:3 share similar specifications, each with an NVIDIA GeForce GTX 1050 Ti having 4GB VRAM. We distribute nine ensembles among the three machines in equal proportions and broadcast their latent representation tensors using ZeroMQ. The PyTorch-based inference script is executed on PC:A, S:1, S:2, and S:3, all having their tensors mapped to a GPU.
Pre-requisites:
[TODO]
A) Distributing the FER Ensemble Branches
To integrate Wrapyfi into the facial expression recognition model
[TODO]
B) Distributing the Transformer Blocks of the Llama LLM
[TODO]
Running the Application
Easy: FER Ensembles on a single machine (horizontal)
[TODO]
Intermediate: FER Ensembles on a multiple machine (horizontal)
[TODO]
Intermediate: LLM Transformer blocks on a multiple machine (vertical)
[TODO]