Latency: Plugin Encoding and Decoding
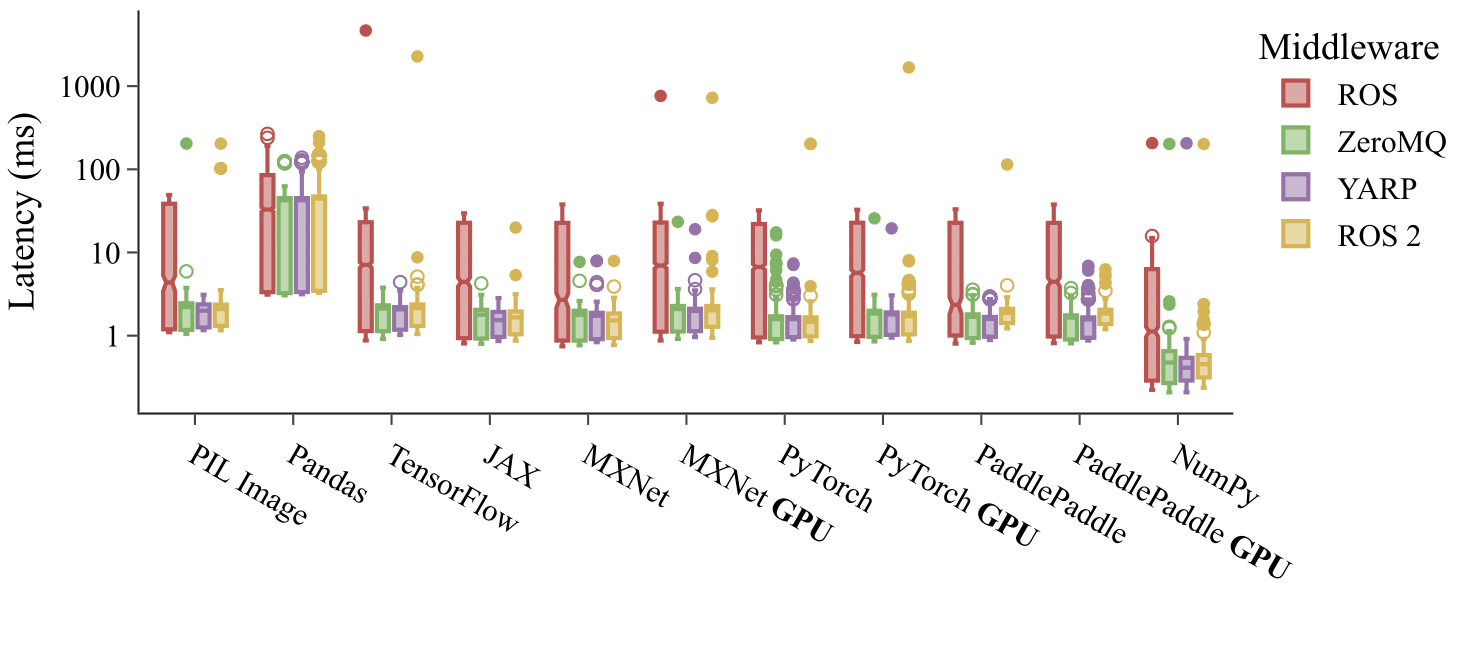
Fig 1: Latency between publishing and receiving 200$\times$200 tensors of ones transmitted using each middleware independently with blocking methods. The transmitted tensors include those of TensorFlow, JAX, MXNet, PyTorch, and PaddlePaddle. 2000 trials are conducted with a publishing rate of 100 Hz for each middleware and plugin combination. Latency indicates the time difference between transmission and reception including de/serialization.
We measure the transmission latency over multiple trials to assess the effectiveness of Wrapyfi in supporting different frameworks and libraries. The results shown in Figure 1 do not reflect the performances of the middleware or libraries themselves but rather those of our serialization and deserialization mechanisms within the given environment. The evaluation was conducted in publishing and subscribing modes on the same machine with an Intel Core i9-11900 running at 2.5 GHz, with 64 GB RAM and an NVIDIA GeForce RTX 3080 Ti GPU with 12 GB VRAM.
We observe NumPy array transmission to result in the lowest latency compared to other data types. This is due to the fact that most plugin encoders are implemented using NumPy arrays. Variances in performance appear most significant with the ROS middleware, which also results in the highest latency on average. The ROS Python bindings serialize messages natively, resulting in additional overhead. GPU tensor mapping to memory shows insignificant delay compared to memory-mapped counterparts in the case of MXNet, PyTorch, and PaddlePaddle. pandas data frames are transmitted with the highest latency owing to their large memory
Warning
Tests conducted using pandas version 1 with a NumPy backend
Compared to NumPy, pandas provides more tools for statistical analysis and data filtration, making it the better option when data management is prioritized. However, given that pandas relies on NumPy or pyArrow as a backend, the latency of encoding and decoding its data types is limited by that of the backend’s. Additionally, the data structure of pandas objects has to be encoded, adding to the overhead.
Running the Benchmarks
The benchmarks are executed using the
benchmarking_native_object.py script.
The script is executed once as a publisher and once as a listener, running simultaneously .
The logs for serialization and deserialization are
saved in the results directory (within the working directory). With the benchmarking script,
we can specify the plugins, the middleware to use, and the
shape of the array/tensor to transmit. The script also allows us to specify the number of trials to conduct and the
publishing rate. The script can be executed as follows:
python benchmarking_native_object.py --listen --plugins pillow numpy --mwares ros yarp --width 200 --height 200 --trials 2000
python benchmarking_native_object.py --publish --plugins pillow numpy --mwares ros yarp --width 200 --height 200 --trials 2000
Warning
ROS and ROS 2 cannot run within the same environment. Therefore, the benchmarks must be executed in separate environments.
The stored files can then be plotted using the jupyter notebook.
Make sure the loaded log files from the results directory are changed according to the latest benchmark runs.